This project features a Job Processing Framework, designed for a typical research process or data-processing operations. The main considerations involved here are 24/7 continuous processing, scalable and fault-tolerant execution. There is also a need for regular re-authentication by authorized authorized personnel to keep the processing running.
In a typical research process, simulation jobs are generated by researcher(s), permutating through different hypothesis or parameters. In certain operational settings, these jobs could be triggered upon new data entry. A linear process will soon be bottle-necked by the processing time. Sometimes, it may even be challenging to do both research and processing simultaneously on one environment.
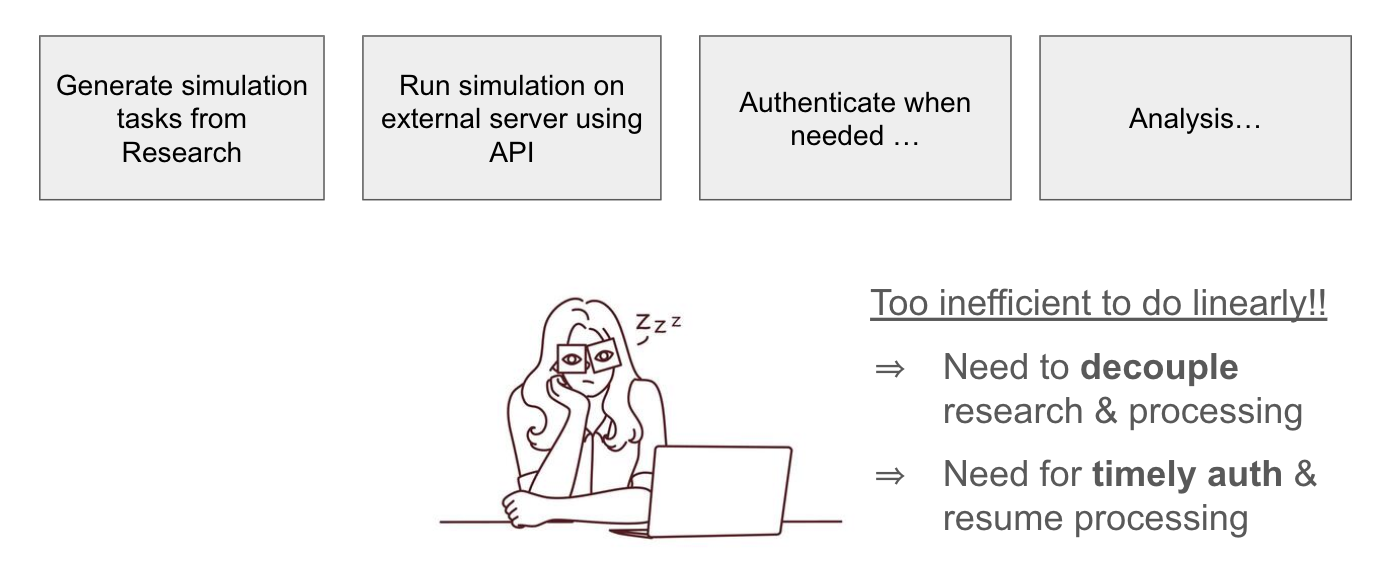
A linear processing framework is inefficient
The solution is to decouple the research and processing processes. By moving the jobs processing and any heavy research processes to the cloud, the research environment now becomes lightweight and focused on analysis.
An SQL Jobs Database (DB) was created to keep track of jobs, and a worker on the cloud to retrieve and process the jobs. The lifecycle of a job is as follow:
- Pending - Queued for processing
- Running - Processing by a worker
- Completed - Successful completion of job by worker with saved results
- Failed - Failed execution of job with logged error message
A valid authentication session is stored in a cache so that it can be retrieved by various processes during its validity period. The status and token expiry is displayed to remind a re-authentication step.
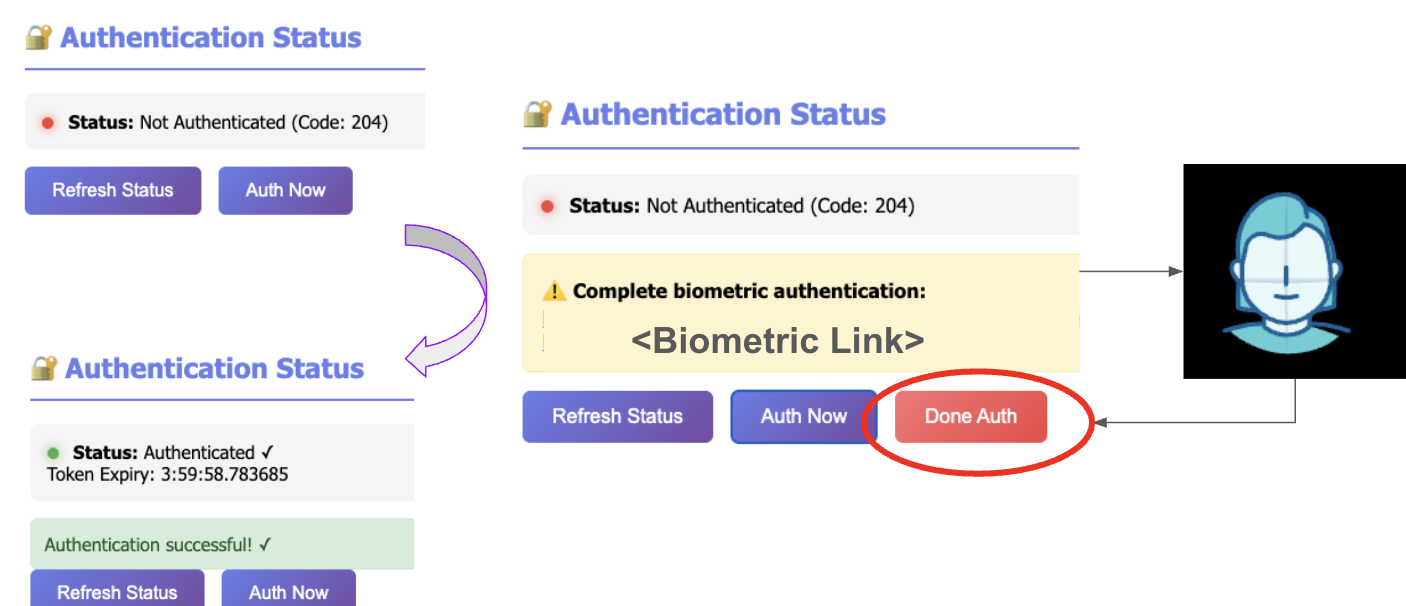
Authentication state transition
Now, we have a framework that decoupled the research and processing workflow, allowing the researcher to work on a lightweight platform to do analysis and generate more jobs to be run on the cloud.
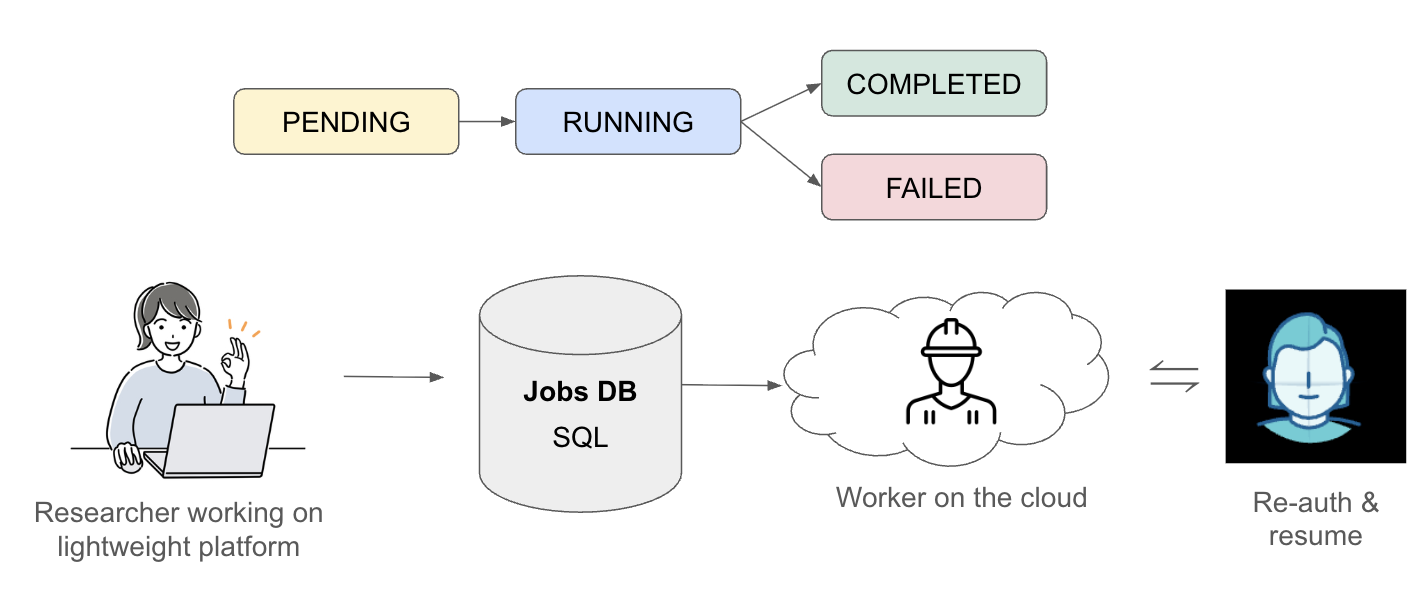
Decoupled research and job processing workflow
Next, to scale up the process, we can increase the number of workers to process more jobs at once. This is not as trivial as just adding workers on the cloud!
Some issues to tackle:
- Workers claiming the same job
- API Throttling
- Auth state transition within worker
- Job state transition within worker
A simple solution for dealing with issue #1 would be to use the queue.Queue() library as a thread-safe in-memory FIFO job queue. This was the initial implementation.
In this case, as API throttling is a common occurrence, jobs that failed n times due to throttle would be re-queued to try again. However, if the jobs are re-queued in the in-memory Queue(), it can form an invisible queue that gets out of control.
Hence, the job queue was re-implemented using semaphore to handle thread locking during job retrieval and log writing. This ensures each job is only claimed and processed by only one worker at a time, and there is no invisible in-memory queue. The pending jobs you see and monitor is the queue itself, and it persists even if the worker restarts.
Another tricky bit in the multi-worker implementation with the re-auth requirement is the transition between valid authentication states and job-waiting states. Sometimes, we observed that some workers wake up from re-authentication while some do not. To investigate this problem, we implemented individual worker log console on top of the main console to have a full visibility of what's happening inside each worker.
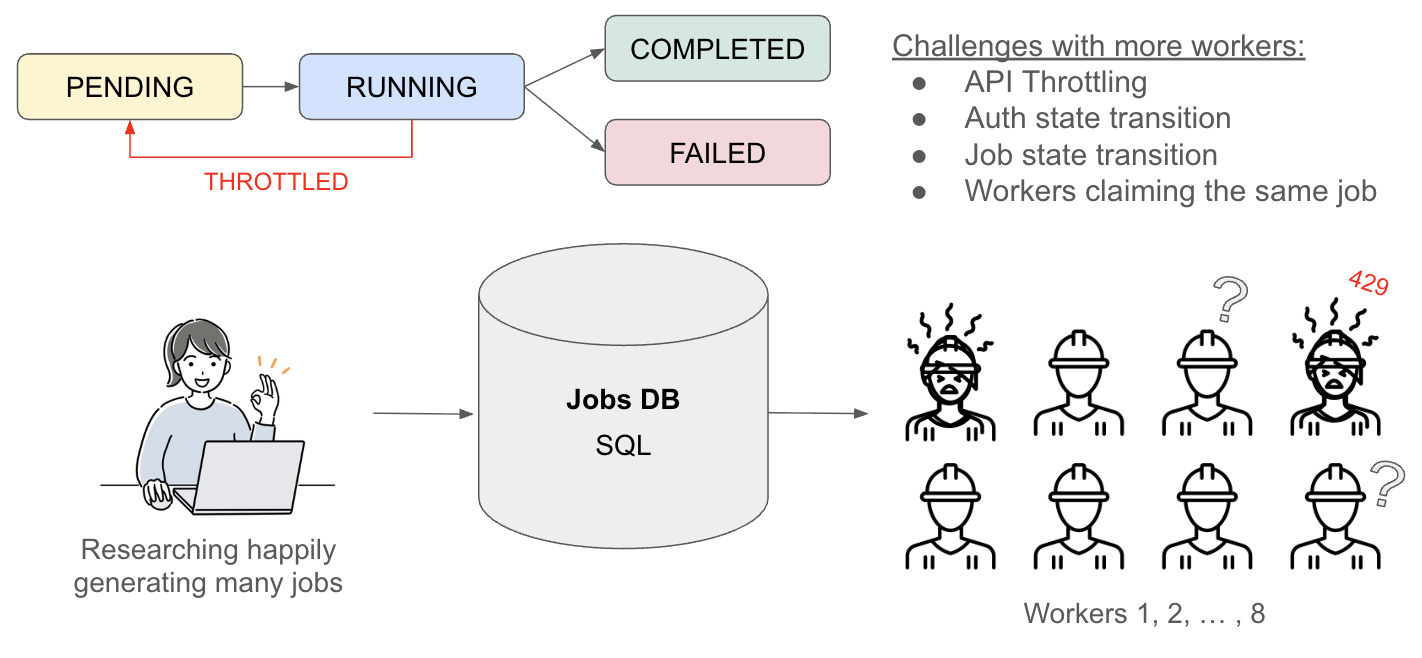
Challenges with a Multi Worker Setup
This is where we found out that some workers were still using an outdated authentication session even when the authentication token has been refreshed, especially when there is no pending jobs. By refreshing the authentication check within the worker before attempting to retrieve a job or process the next job, it will then be able to transition between the authentication state and job states correctly.
The point made here is not about the solution to the problem, but the process of investigation through logging and visualization. In fact, most of the time the difficult parts is figuring where the problem lies. The easy (and satisfying) part is to solve the problem.
This incident reinforced a core principle of the framework: systems must be observable before they can be reliable.
Here's the flowchart to summarize the job processing workflow for multiple workers.
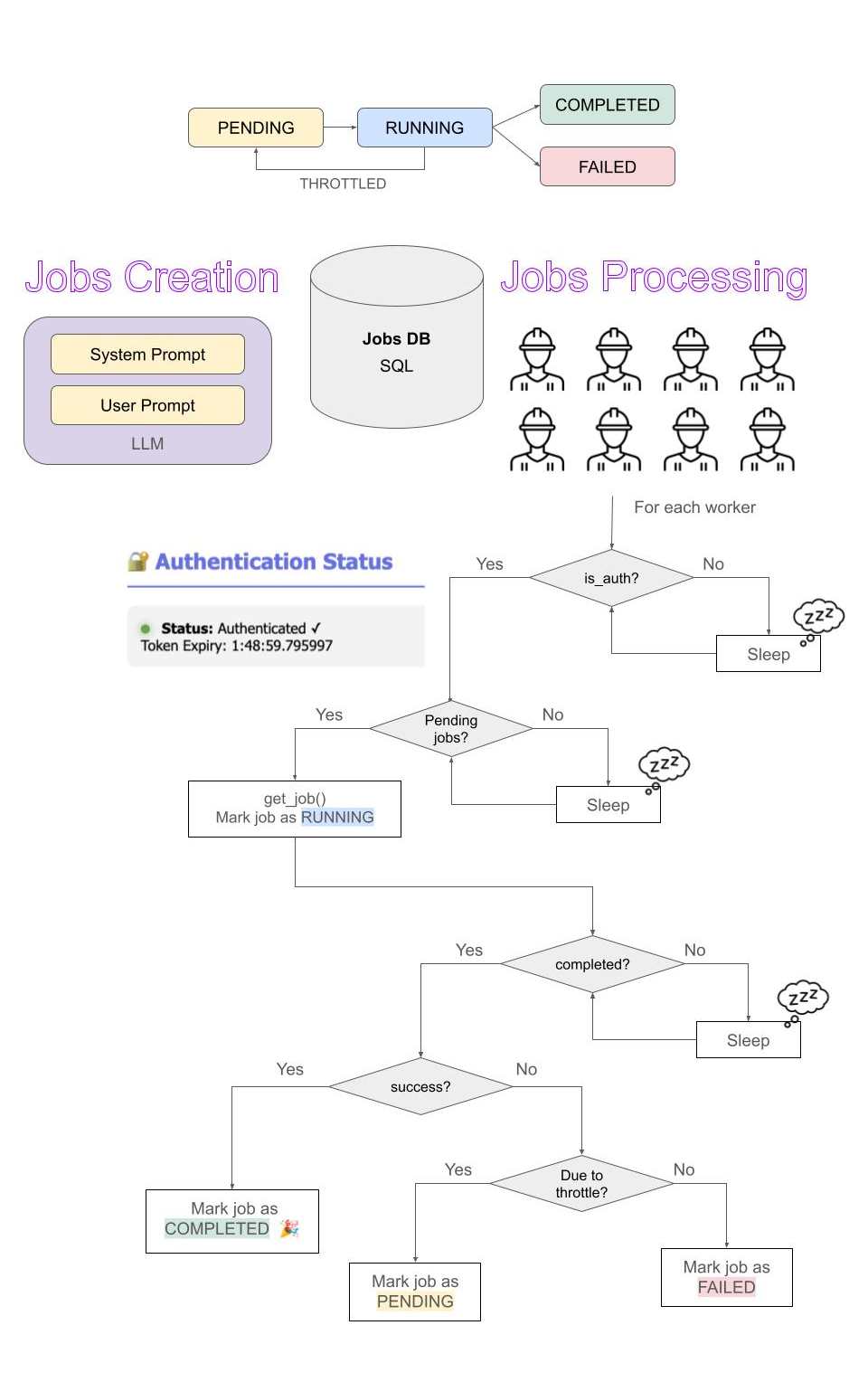
Jobs Processing Flowchart